Econometrics is the unification of economics, mathematics, and statistics. This unification produces more than the sum of its parts.[5] Econometrics adds empirical content to economic theory allowing theories to be tested and used for forecasting and policy evaluation.[6]
Contents[hide] |
[edit] Basic econometric models: linear regression
The basic tool for econometrics is the linear regression model. In modern econometrics, other statistical tools are frequently used, but linear regression is still the most frequently used starting point for an analysis.[7] Estimating a linear regression on two variables can be visualized as fitting a line through data points representing paired values of the independent and dependent variables.
 ) is a function of an intercept (
) is a function of an intercept ( ), a given value of GNP growth multiplied by a slope coefficient
), a given value of GNP growth multiplied by a slope coefficient  and an error term,
and an error term,  :
: and can be estimated. Here is estimated to be -1.77 and is estimated to be 0.83. This means that if GNP grew one point faster, the unemployment rate would be predicted to drop by .94 points (-1.77*1+0.83). The model could then be tested for statistical significance as to whether an increase in growth is associated with a decrease in the unemployment, as hypothesized. If the estimate of were not significantly different from 0, we would fail to find evidence that changes in the growth rate and unemployment rate were related.
and can be estimated. Here is estimated to be -1.77 and is estimated to be 0.83. This means that if GNP grew one point faster, the unemployment rate would be predicted to drop by .94 points (-1.77*1+0.83). The model could then be tested for statistical significance as to whether an increase in growth is associated with a decrease in the unemployment, as hypothesized. If the estimate of were not significantly different from 0, we would fail to find evidence that changes in the growth rate and unemployment rate were related.[edit] Theory
See also: Estimation theory
Econometric theory uses statistical theory to evaluate and develop econometric methods. Econometricians try to find estimators that have desirable statistical properties including unbiasedness, efficiency, and consistency. An estimator is unbiased if its expected value is the true value of the parameter; It is consistent if it converges to the true value as sample size gets larger, and it is efficient if the estimator has lower standard error than other unbiased estimators for a given sample size. Ordinary least squares (OLS) is often used for estimation since it provides the BLUE or "best linear unbiased estimator" (where "best" means most efficient, unbiased estimator) given the Gauss-Markov assumptions. When these assumptions are violated or other statistical properties are desired, other estimation techniques such as maximum likelihood estimation, generalized method of moments, or generalized least squares are used. Estimators that incorporate prior beliefs are advocated by those who favor Bayesian statistics over traditional, classical or "frequentist" approaches.[edit] Gauss-Markov theorem
The Gauss-Markov theorem shows that the OLS estimator is the best (minimum variance), unbiased estimator assuming the model is linear, the expected value of the error term is zero, errors are homoskedastic and not autocorrelated, and there is no perfect multicollinearity.[edit] Linearity
The dependent variable is assumed to be a linear function of the variables specified in the model. The specification must be linear in its parameters. This does not mean that there must be a linear relationship between the independent and dependent variables. The independent variables can take non-linear forms as long as the parameters are linear. The equation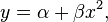 qualifies as linear while
qualifies as linear while  , does not.
, does not.Data transformations can be used to convert an equation into a linear form. For example, the Cobb-Douglas equation—often used in economics—is nonlinear:


This assumption also covers specification issues: assuming that the proper functional form has been selected and there are no omitted variables.
[edit] Expected error is zero
![\operatorname{E}[\,\varepsilon\,] = 0.](http://upload.wikimedia.org/math/1/e/e/1eefe47c2c5fce0c60c282943e1188e8.png)
The intercept may also be biased if there is a logarithmic transformation. See the Cobb-Douglas equation above. The multiplicative error term will not have a mean of 0, so this assumption will be violated.[10]
This assumption can also be violated in limited dependent variable models. In such cases, both the intercept and slope parameters may be biased.[11]
[edit] Spherical errors
![\operatorname{Var}[\,\varepsilon|X\,] = \sigma^2 I_n,](http://upload.wikimedia.org/math/4/d/0/4d08b921b3ba8776a302bcd25a939f99.png)
![\operatorname{Var}[\,\varepsilon|X\,] = \sigma^2 I_n](http://upload.wikimedia.org/math/0/2/6/026b4c3d89c63f0499871bc4d76c95cd.png) in the multivariate normal density, then the equation f(x)=c is the formula for a “ball” centered at μ with radius σ in n-dimensional space.[13]
in the multivariate normal density, then the equation f(x)=c is the formula for a “ball” centered at μ with radius σ in n-dimensional space.[13]Heteroskedacity occurs when the amount of error is correlated with an independent variable. For example, in a regression on food expenditure and income, the error is correlated with income. Low income people generally spend a similar amount on food, while high income people may spend a very large amount or as little as low income people spend. Heteroskedacity can also be caused by changes in measurement practices. For example, as statistical offices improve their data, measurement error decreases, so the error term declines over time.
This assumption is violated when there is autocorrelation. Autocorrelation can be visualized on a data plot when a given observation is more likely to lie above a fitted line if adjacent observations also lie above the fitted regression line. Autocorrelation is common in time series data where a data series may experience "inertia."[14] If a dependent variable takes a while to fully absorb a shock. Spatial autocorrelation can also occur geographic areas are likely to have similar errors. Autocorrelation may be the result of misspecification such as choosing the wrong functional form. In these cases, correcting the specification is the preferred way to deal with autocorrelation.
In the presence of non-spherical errors, the generalized least squares estimator can be shown to be BLUE.[15]
[edit] Exogeneity of independent variables
![\operatorname{E}[\,\varepsilon|X\,] = 0.](http://upload.wikimedia.org/math/e/9/e/e9e8f5ad21a01e409bd90ad0950dfa62.png)
[edit] Full rank
The sample data matrix must have full rank or OLS cannot be estimated. There must be at least one observation for every parameter being estimated and the data cannot have perfect multicollinearity.[16] Perfect multicollinearity will occur in a "dummy variable trap" when a base dummy variable is not omitted resulting in perfect correlation between the dummy variables and the constant term.Multicollinearity (as long as it is not "perfect") can be present resulting in a less efficient, but still unbiased estimate.
[edit] Methods
See also: Methodology of econometrics
Applied econometrics uses theoretical econometrics and real-world data for assessing economic theories, developing econometric models, analyzing economic history, and forecasting.[17]Econometrics may use standard statistical models to study economic questions, but most often they are with observational data, rather than in controlled experiments. In this, the design of observational studies in econometrics is similar to the design of studies in other observational disciplines, such as astronomy, epidemiology, sociology and political science. Analysis of data from an observational study is guided by the study protocol, although exploratory data analysis may by useful for generating new hypotheses.[18] Economics often analyzes systems of equations and inequalities, such as supply and demand hypothesized to be in equilibrium. Consequently, the field of econometrics has developed methods for identification and estimation of simultaneous-equation models. These methods are analogous to methods used in other areas of science, such as the field of system identification in systems analysis and control theory. Such methods may allow researchers to estimate models and investigate their empirical consequences, without directly manipulating the system.
One of the fundamental statistical methods used by econometricians is regression analysis. For an overview of a linear implementation of this framework, see linear regression. Regression methods are important in econometrics because economists typically cannot use controlled experiments. Econometricians often seek illuminating natural experiments in the absence of evidence from controlled experiments. Observational data may be subject to omitted-variable bias and a list of other problems that must be addressed using causal analysis of simultaneous-equation models.[19]
[edit] Experimental economics
In recent decades, econometricians have increasingly turned to use of experiments to evaluate the often-contradictory conclusions of observational studies. Here, controlled and randomized experiments provide statistical inferences that may yield better empirical performance than do purely observational studies.[20][edit] Data
Data sets to which econometric analyses are applied can be classified as time-series data, cross-sectional data, panel data, and multidimensional panel data. Time-series data sets contain observations over time; for example, inflation over the course of several years. Cross-sectional data sets contain observations at a single point in time; for example, many individuals' incomes in a given year. Panel data sets contain both time-series and cross-sectional observations. Multi-dimensional panel data sets contain observations across time, cross-sectionally, and across some third dimension. For example, the Survey of Professional Forecasters contains forecasts for many forecasters (cross-sectional observations), at many points in time (time series observations), and at multiple forecast horizons (a third dimension).[edit] Instrumental variables
In many econometric contexts, the commonly-used ordinary least squares method may not recover the theoretical relation desired or may produce estimates with poor statistical properties, because the assumptions for valid use of the method are violated. One widely-used remedy is the method of instrumental variables (IV). For an economic model described by more than one equation, simultaneous-equation methods may be used to remedy similar problems, including two IV variants, Two-Stage Least Squares (2SLS), and Three-Stage Least Squares (3SLS).[21][edit] Computational methods
Computational concerns are important for evaluating econometric methods and for use in decision making.[22] Such concerns include mathematical well-posedness: the existence, uniqueness, and stability of any solutions to econometric equations. Another concern is the numerical efficiency and accuracy of software.[23] A third concern is also the usability of econometric software.[24][edit] Example
A simple example of a relationship in econometrics from the field of labor economics is: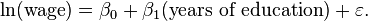 measures the increase in the natural log of the wage attributable to one more year of education. The term
measures the increase in the natural log of the wage attributable to one more year of education. The term  is a random variable representing all other factors that may have direct influence on wage. The econometric goal is to estimate the parameters,
is a random variable representing all other factors that may have direct influence on wage. The econometric goal is to estimate the parameters,  under specific assumptions about the random variable . For example, if is uncorrelated with years of education, then the equation can be estimated with ordinary least squares.
under specific assumptions about the random variable . For example, if is uncorrelated with years of education, then the equation can be estimated with ordinary least squares.If the researcher could randomly assign people to different levels of education, the data set thus generated would allow estimation of the effect of changes in years of education on wages. In reality, those experiments cannot be conducted. Instead, the econometrician observes the years of education of and the wages paid to people who differ along many dimensions. Given this kind of data, the estimated coefficient on Years of Education in the equation above reflects both the effect of education on wages and the effect of other variables on wages, if those other variables were correlated with education. For example, people born in certain places may have higher wages and higher levels of education. Unless the econometrician controls for place of birth in the above equation, the effect of birthplace on wages may be falsely attributed to the effect of education on wages.
The most obvious way to control for birthplace is to include a measure of the effect of birthplace in the equation above. Exclusion of birthplace, together with the assumption that
is uncorrelated with education produces a misspecified model. Another technique is to include in the equation additional set of measured covariates which are not instrumental variables, yet render identifiable.[25] An overview of econometric methods used to study this problem can be found in Card (1999).[26][edit] Journals
The main journals which publish work in econometrics are Econometrica, the Journal of Econometrics, the Review of Economics and Statistics, Econometric Theory, the Journal of Applied Econometrics, Econometric Reviews, the Econometrics Journal,[27] Applied Econometrics and International Development, the Journal of Business & Economic Statistics, and the Journal of Economic and Social Measurement.[edit] Limitations and criticisms
-
- See also Criticisms of econometrics
In some cases, economic variables cannot be experimentally manipulated as treatments randomly assigned to subjects.[30] In such cases, economists rely on observational studies, often using data sets with many strongly associated covariates, resulting in enormous numbers of models with similar explanatory ability but different covariates and regression estimates. Regarding the plurality of models compatible with observational data-sets, Edward Leamer urged that "professionals ... properly withhold belief until an inference can be shown to be adequately insensitive to the choice of assumptions".[31]
Economists from the Austrian School argue that aggregate economic models are not well suited to describe economic reality because they waste a large part of specific knowledge. Friedrich Hayek in his The Use of Knowledge in Society argued that "knowledge of the particular circumstances of time and place" is not easily aggregated and is often ignored by professional economists.[32][33]
[edit] See also
- Augmented Dickey–Fuller test
- Choice Modelling
- Correlation does not imply causation
- Cowles Foundation
- Criticisms of econometrics
- Econometric software
- Granger causality
- Important publications in econometrics
- Lucas critique
- Macroeconomic model
- Master of Economics
- Methodological individualism
- Methodology of econometrics
- Modeling and analysis of financial markets
- Predetermined variables
- Single equation methods (econometrics)
- Spatial econometrics
- Unit root
[edit] Notes
- ^ M. Hashem Pesaran (1987). "Econometrics," The New Palgrave: A Dictionary of Economics, v. 2, p. 8 [pp. 8-22]. Reprinted in J. Eatwell et al., eds. (1990). Econometrics: The New Palgrave, p. 1 [pp. 1-34]. Abstract (2008 revision by J. Geweke, J. Horowitz, and H. P. Pesaran).
- ^ P. A. Samuelson, T. C. Koopmans, and J. R. N. Stone (1954). "Report of the Evaluative Committee for Econometrica," Econometrica 22(2), p. 142. [p p. 141-146], as described and cited in Pesaran (1987) above.
- ^ Paul A. Samuelson and William D. Nordhaus, 2004. Economics. 18th ed., McGraw-Hill, p. 5.
- ^ • H. P. Pesaran (1990), "Econometrics," Econometrics: The New Palgrave, p. 2, citing Ragnar Frisch (1936), "A Note on the Term 'Econometrics'," Econometrica, 4(1), p. 95.
• Aris Spanos (2008), "statistics and economics," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract. - ^ Greene, 1.
- ^ Geweke, Horowitz & Pesaran 2008.
- ^ Greene (2012), 12.
- ^ Kennedy 2003, p. 110.
- ^ Kennedy 2003, p. 129.
- ^ Kennedy 2003, p. 131.
- ^ Kennedy 2003, p. 130.
- ^ Kennedy 2003, p. 133.
- ^ Greene 2012, p. 23-note.
- ^ Greene 2010, p. 22.
- ^ Kennedy 2003, p. 135.
- ^ Kennedy 2003, p. 205.
- ^ Clive Granger (2008). "forecasting," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract.
- ^ Herman O. Wold (1969). "Econometrics as Pioneering in Nonexperimental Model Building," Econometrica, 37(3), pp. 369-381.
- ^ Edward E. Leamer (2008). "specification problems in econometrics," The New Palgrave Dictionary of Economics. Abstract.
- ^ • H. Wold 1954. "Causality and Econometrics," Econometrica, 22(2), p p. 162-177.
• Kevin D. Hoover (2008). "causality in economics and econometrics," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract and galley proof. - ^ Peter Kennedy (economist) (2003). A Guide to Econometrics, 5th ed. Description, preview, and TOC, ch. 9, 10, 13, and 18.
- ^ • Keisuke Hirano (2008). "decision theory in econometrics," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract.
• James O. Berger (2008). "statistical decision theory," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract. - ^ B. D. McCullough and H. D. Vinod (1999). "The Numerical Reliability of Econometric Software," Journal of Economic Literature, 37(2), pp. 633-665.
- ^ • Vassilis A. Hajivassiliou (2008). "computational methods in econometrics," The New Palgrave Dictionary of Economics, 2nd Edition. Abstract.
• Richard E. Quandt (1983). "Computational Problems and Methods," ch. 12, in Handbook of Econometrics, v. 1, pp. 699-764.
• Ray C. Fair (1996). "Computational Methods for Macroeconometric Models," Handbook of Computational Economics, v. 1, pp. [1]-169. - ^ Judea Pearl (2000). Causality: Model, Reasoning, and Inference, Cambridge University Press.
- ^ David Card (1999) "The Causal Effect of Education on Earning," in Ashenfelter, O. and Card, D., (eds.) Handbook of Labor Economics, pp 1801-63.
- ^ http://www.wiley.com/bw/journal.asp?ref=1368-4221
- ^ McCloskey (May 1985). "The Loss Function has been mislaid: the Rhetoric of Significance Tests". American Economic Review 75 (2).
- ^ Stephen T. Ziliak and Deirdre N. McCloskey (2004). "Size Matters: The Standard Error of Regressions in the American Economic Review," Journal of Socio-economics, 33(5), pp. 527-46 (press +).
- ^ Leamer, Edward (March 1983). "Let's Take the Con out of Econometrics". American Economic Review 73 (1): 34. http://www.jstor.org/pss/1803924.
- ^ Leamer, Edward (March 1983). "Let's Take the Con out of Econometrics". American Economic Review 73 (1): 43. http://www.jstor.org/pss/1803924.
- ^ Robert F. Garnett. What Do Economists Know? New Economics of Knowledge. Routledge, 1999. ISBN 978-0-415-15260-0. p. 170
- ^ G. M. P. Swann. Putting Econometrics in Its Place: A New Direction in Applied Economics. Edward Elgar Publishing, 2008. ISBN 978-1-84720-776-0. p. 62-64
[edit] References
- Handbook of Econometrics Elsevier. Links to volume chapter-preview links:
Zvi Griliches and Michael D. Intriligator, ed. (1983). v. 1; (1984),v. 2; (1986), description, v. 3; (1994), description, v. 4
Robert F. Engle and Daniel L. McFadden, ed. (2001).Description, v. 5
James J. Heckman and Edward E. Leamer, ed. (2007). Description, v. 6A & v. 6B - Handbook of Statistics, v. 11, Econometrics (1993), Elsevier. Links to first-page chapter previews.
- International Encyclopedia of the Social & Behavioral Sciences (2001), Statistics, "Econometrics and Time Series," links to first-page previews of 21 articles.
- Angrist, Joshua & Pischke, Jörn‐Steffen (2010). "The Credibility Revolution in Empirical Economics: How Better Research Design Is Taking the Con out of Econometrics], 24(2), , pp. 3–30. Abstract.
- Eatwell, John, et al., eds. (1990). Econometrics: The New Palgrave. Article-preview links (from The New Palgrave: A Dictionary of Economics, 1987).
- Geweke, John; Horowitz, Joel; Pesaran, Hashem (2008). Durlauf, Steven N.; Blume, Lawrence E.. eds. "Econometrics". The New Palgrave Dictionary of Economics (Palgrave Macmillan). doi:10.1057/9780230226203.0425. http://www.dictionaryofeconomics.com.proxyau.wrlc.org/article?id=pde2008_E000007.
- Greene, William H. (1999, 4th ed.) Econometric Analysis, Prentice Hall.
- Hayashi, Fumio. (2000) Econometrics, Princeton University Press. ISBN 0-691-01018-8 Description and contents links.
- Hamilton, James D. (1994) Time Series Analysis, Princeton University Press. Description and preview.
- Hughes Hallett, Andrew J. "Econometrics and the Theory of Economic Policy: The Tinbergen-Theil Contributions 40 Years On," Oxford Economic Papers (1989) 41#1 pp 189-214
- Kelejian, Harry H., and Wallace E. Oates (1989, 3rd ed.) Introduction to Econometrics.
- Kennedy, Peter (2003). A guide to econometrics. Cambridge, Mass: MIT Press. ISBN 978-0-262-61183-1.
- Russell Davidson and James G. MacKinnon (2004). Econometric Theory and Methods. New York: Oxford University Press. Description.
- Mills, Terence C., and Kerry Patterson, ed. Palgrave Handbook of Econometrics:
- (2007) v. 1: Econometric Theoryv. 1. Links to description and contents.
- (2009) v. 2, Applied Econometrics. Palgrave Macmillan. ISBN 978-1-4039-1799-7 Links to description and contents.
- Pearl, Judea (2009, 2nd ed.). Causality: Models, Reasoning and Inference, Cambridge University Press, Description, TOC, and preview, ch. 1-10 and ch. 11. 5 economics-journal reviews, including Kevin D. Hoover, Economics Journal.
- Pindyck, Robert S., and Daniel L. Rubinfeld (1998, 4th ed.). Econometric Methods and Economic Forecasts, McGraw-Hill.
- Studenmund, A.H. (2011, 6th ed.). Using Econometrics: A Practical Guide. Contents (chapter-preview) links.
- Wooldridge, Jeffrey (2003). Introductory Econometrics: A Modern Approach. Mason: Thomson South-Western. ISBN 0-324-11364-1 Chapter-preview links in brief and detail.
[edit] Further reading
- Econometric Theory book on Wikibooks
- Giovanini, Enrico Understanding Economic Statistics, OECD Publishing, 2008, ISBN 978-92-64-03312-2
[edit] External links
| Look up econometrics in Wiktionary, the free dictionary. |
- Econometric Society
- The Econometrics Journal
- Econometric Links
- Teaching Econometrics (Index by the Economics Network (UK))
- Applied Econometric Association
- The Society for Financial Econometrics
| ||
No comments:
Post a Comment